Data Science Weekly - Issue 603Curated news, articles and jobs related to Data Science, AI, & Machine Learning
Issue #603 |

 |
Find your algorithm for success with a Master’s in Data Science from Drexel University. Gain essential skills in tool creation and development, data and text mining, trend identification, and data manipulation and summarization by using leading industry technology to apply to your career. Learn more.
.
.
* Want to sponsor the newsletter? Email us for details --> team@datascienceweekly.org
What’s on your mind
This Week’s Poll:
|
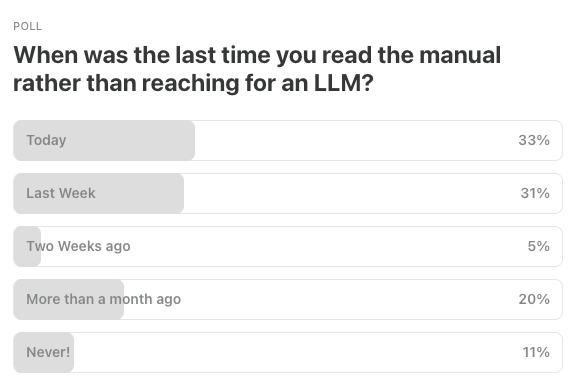
Last Week’s Poll:
 |
.
Data Science Articles & Videos
Doing Data Analysis with AI - A short course
This course will equip students, who are already versed in core data analysis methods, with experience to harness AI technologies to improve productivity (yes this is classic LLM sentence)…But, yeah, the idea is to help students who studied data analysis / econometrics / quant methods and want to think about how to include AI in their analytics routine, and spend time to share experiences…This is the 2025 Spring edition release..Life Sequence Transformer: Generative Modelling for Counterfactual Simulation
Social sciences rely on counterfactual analysis using surveys and administrative data, generally depending on strong assumptions or the existence of suitable control groups, to evaluate policy interventions and estimate causal effects. We propose a novel approach that leverages the Transformer architecture to simulate counterfactual life trajectories from large-scale administrative records…What is dangerous for pregnant women? Not that much, stop worrying
There's a very large literature on the outcomes of children to mothers who did X. The problem with most of these is that mothers who do and don't do X are not necessarily otherwise comparable to mothers who didn't do X. In other words, the primary problem of social science applies, that of self-selection. So what can we do about this problem? Well, nature has been kind enough to make siblings. They are very useful because they don't differ in certain ways…What is the best IDE for data science in 2025? [Reddit]
I am a "old" data scientists looking to renew my stacks. Looking for opinions on what is the best IDE in 2025. The other discussion I found was 1 year ago and some even older. So what do you use as IDE for data science (data extraction, cleaning, modeling to deployment)? What do you like and what you don't like about it?…Get your data ducks in a row with DuckLake
There’s a new data lake on the market: DuckLake. It’s worth the hype because it gives you an open standard that not only enables you to run queries on your data lakes from anywhere, it outright encourages you to run your query, metadata, and storage layers separately in whatever platform works best for you. We've been thinking about DuckDB as a solution for Small Data, but now with the limitless storage capability of object storage, it can support massive scale datasets…Coordinated Progress – Part 1 – Seeing the System: The Graph
At some point, we’ve all sat in an architecture meeting where someone asks, “Should this be an event? An RPC? A queue?”, or “How do we tie this process together across our microservices? Should it be event-driven? Maybe a workflow orchestration?” Cue a flurry of opinions, whiteboard arrows, and vague references to sagas…Now that I work for a streaming data infra vendor, I get asked: “How do event-driven architecture, stream processing, orchestration, and the new durable execution category relate to one another?”…These are deceptively broad questions, touching everything from architectural principles to practical trade-offs. To be honest, I had an instinctual understanding of how they fit together but I’d never written it down. Coordinated Progress is a 4-part series describing how I see it, my mental framework, and hopefully it will be useful and understandable to you.Cascading retrieval with multi-vector representations: balancing efficiency and effectiveness
In this blog post, we will:Highlight the limitations of simple retrieve-and-rerank pipelines and the need for multi-vector models.
Introduce the concept of a multi-step reranking approach that uses multi-vector embeddings at scale to increase accuracy, followed by cross-encoder re-ranking for the final step.
Present ConstBERT, a constant-space multi-vector retrieval model, developed through a collaboration between Pinecone, Sean MacAvaney (University of Glasgow), and professor Nicola Tonellotto (University of Pisa), that reduces storage overhead while maintaining effectiveness.
By the end of this post, you'll have a practical roadmap for implementing efficient and scalable multi-vector retrieval within Pinecone, ensuring that search remains both fast and accurate
Who is the best data scientist you've ever worked with? (Twitter/X Thread)

…
One Law to Rule All Code Optimizations
In this article, I show you one law that explains all low-level code optimizations: when they work, and when they don’t. It’s based on the Iron Law of Performance, a model widely known in the hardware world but relatively obscure in software circles…What we’ll see is that almost every low-level optimization, whether it's loop unrolling, SIMD vectorization, or branch elimination, ultimately affects just three metrics: the number of instructions executed, the number of cycles needed to execute them, and the duration of a single cycle…
Welcome to the latest issue of your guide to AI, an editorialized newsletter covering the key developments in AI policy, research, industry, and start-ups over the last month…
Old Maps Online - Digital Map Collection
Discover history through OldMapsOnline…Browse historical places and search for old maps with timeline…MCP vs API
Every week a new thread emerges on Reddit asking about the difference between MCP and API. I've tried summarizing everything that's been said about MCP vs API in a single post (and a single table)…Scalable Lakehouse Architecture with Iceberg & Polaris: A Battle-tested Playbook
How can modern data teams achieve massive scalability, flexibility, and efficiency while avoiding the pitfalls of fragmented data lakes? This session explores Taktile's journey from a complex mix of S3, Glue, and Snowflake to a fully integrated, pythonic Lakehouse with Apache Iceberg, Polaris Catalog, and dlt. See how they scaled from gigabytes to terabytes, solved high-rate event ingestion, and unified their architecture for a future-proof data stack…
.
Last Week's Newsletter's 3 Most Clicked Links
.
* Based on unique clicks.
** Find last week's issue #602 here.
Cutting Room Floor
On a few pitfalls in KL divergence gradient estimation for RL
How Do Transformers Learn Variable Binding in Symbolic Programs?
From data to insights: Entity-resolved knowledge graphs with Kuzu & Senzing
.
Whenever you're ready, 3 ways we can help:
Want to get better at Data Science / Machine Learning Math? I have a zero weekly tutoring slots open. Hit reply to this email and let me know what you want to learn. I’ll add you to the waitlist.
Looking to get a job? Check out our “Get A Data Science Job” Course
It is a comprehensive course that teaches you everything related to getting a data science job based on answers to thousands of emails from readers like you. The course has 3 sections: Section 1 covers how to get started, Section 2 covers how to assemble a portfolio to showcase your experience (even if you don’t have any), and Section 3 covers how to write your resume.Promote yourself/organization to ~68,400 subscribers by sponsoring this newsletter. 30-40% weekly open rate.
Thank you for joining us this week! :)
Stay Data Science-y!
All our best,
Hannah & Sebastian
Invite your friends and earn rewards
![]()
![]()
Комментариев нет:
Отправить комментарий
Примечание. Отправлять комментарии могут только участники этого блога.